C++基础
C++知识
C++内存基础
进程虚拟空间地址划分
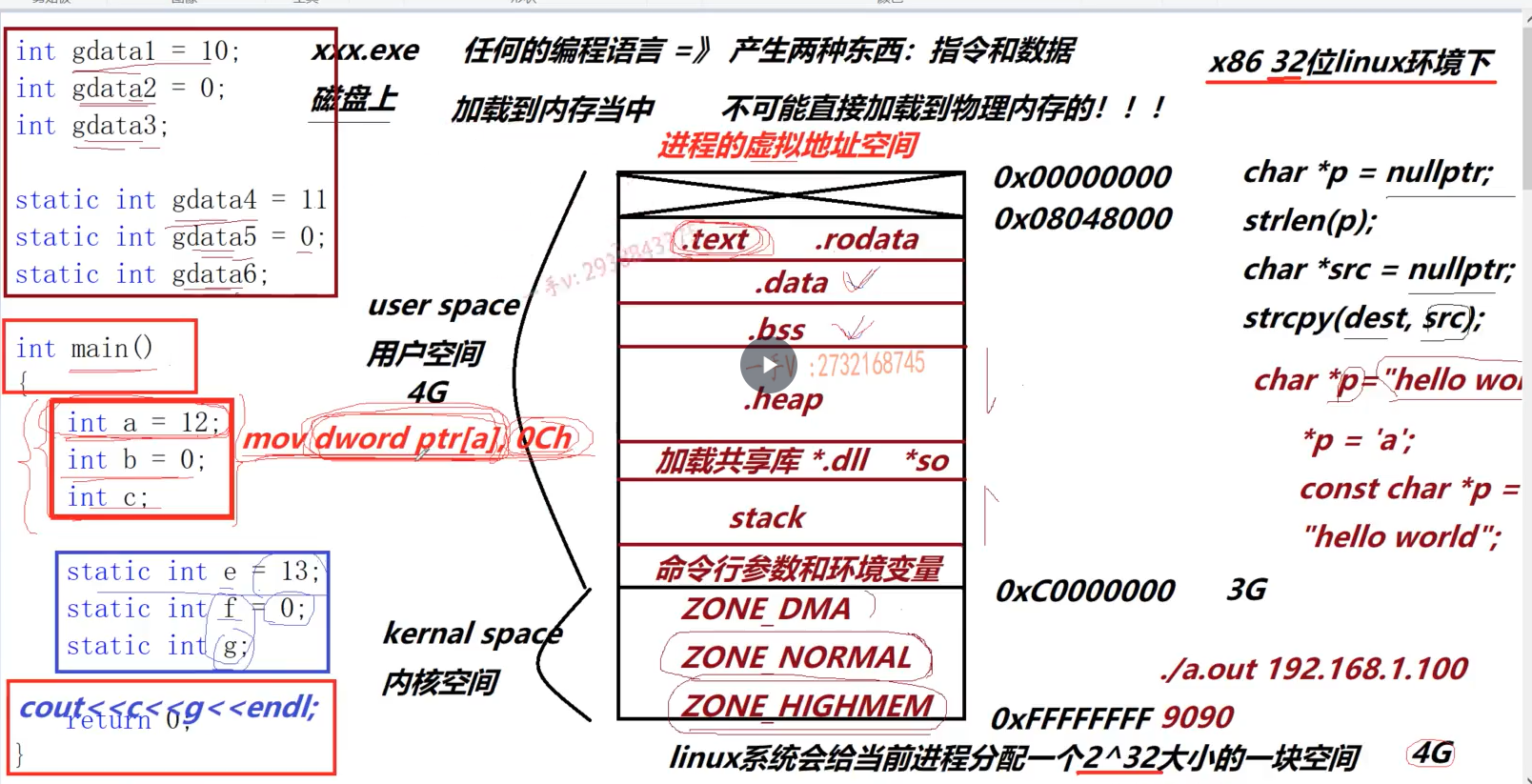
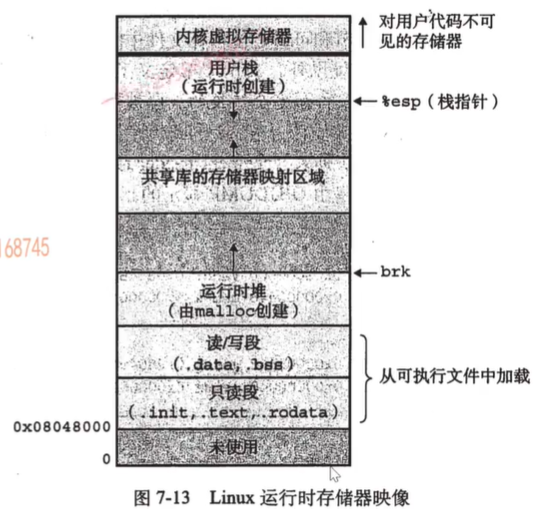
- 指令在运行的时候存放在在.text段;数据放在.data和.bbs段
- .data:存放已经初始化的数据且数据不为0
- .bbs:存放未初始化的数据(系统会赋值为0,所以打印未初始化的数据会输出为0)
- 程序内局部变量都是指令;全局变量和静态变量都是数据
- 指令存放在.text段,而指令执行的时候会在栈上开辟空间
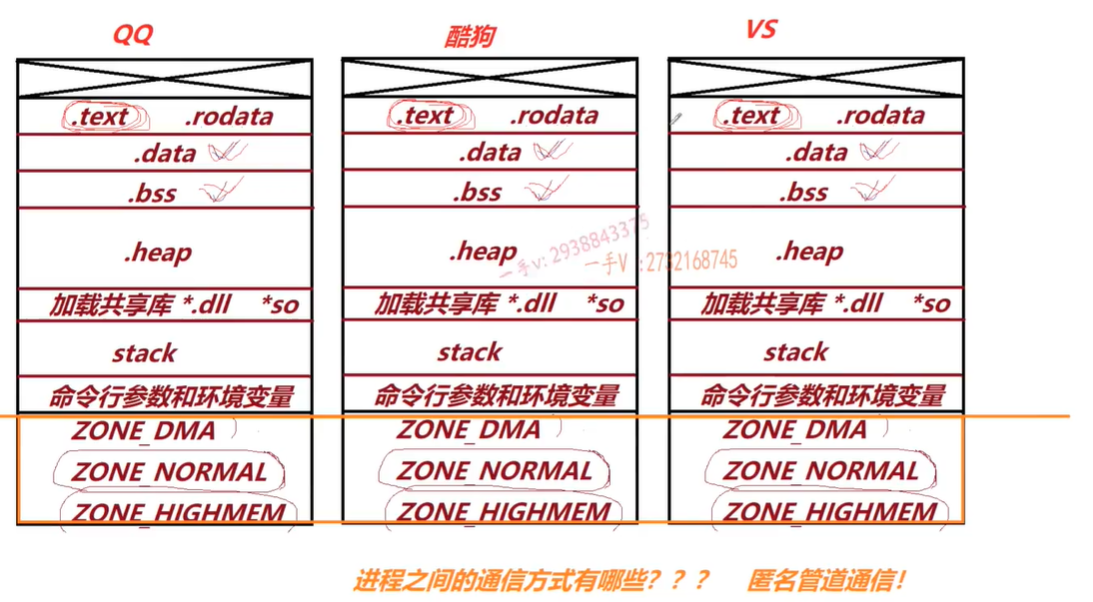
- 对于不同的线程,用户空间是隔离的,内核空间是共享的
- 管道通信实际上是在内核空间划分了内存,所以才能通信,因为用户空间是隔离的
从编译器角度理解C++代码的编译和链接原理
- 编译过程如下:
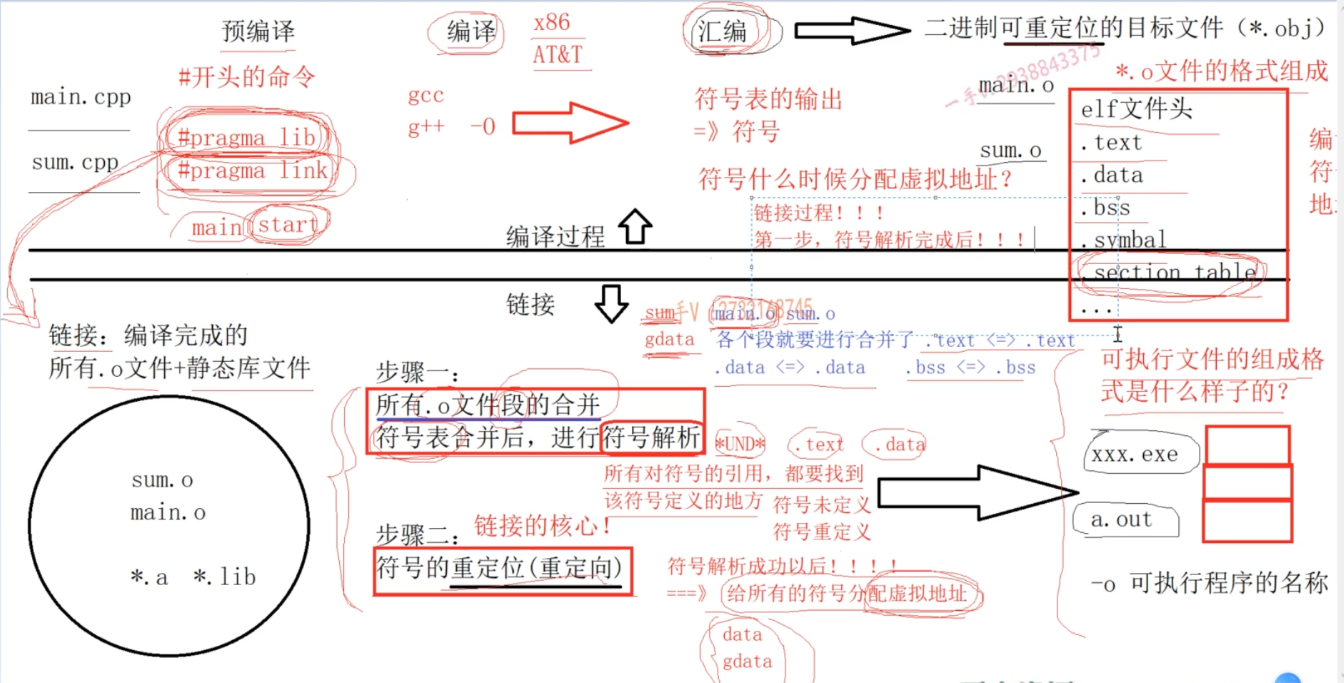
编译生成的.o文件组成
- 这里的每一行称为段
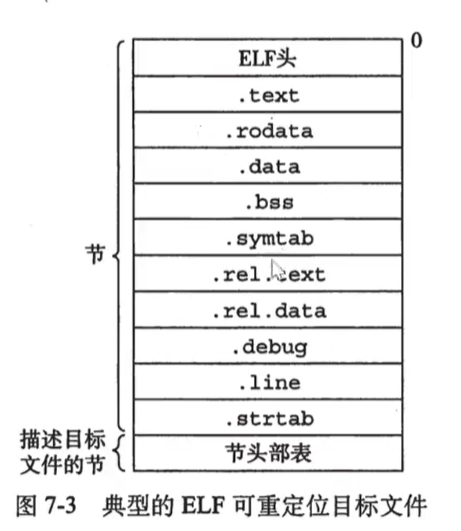
- 这里的每一行称为段
编译中的符号表

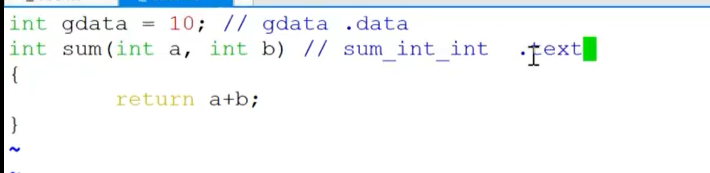
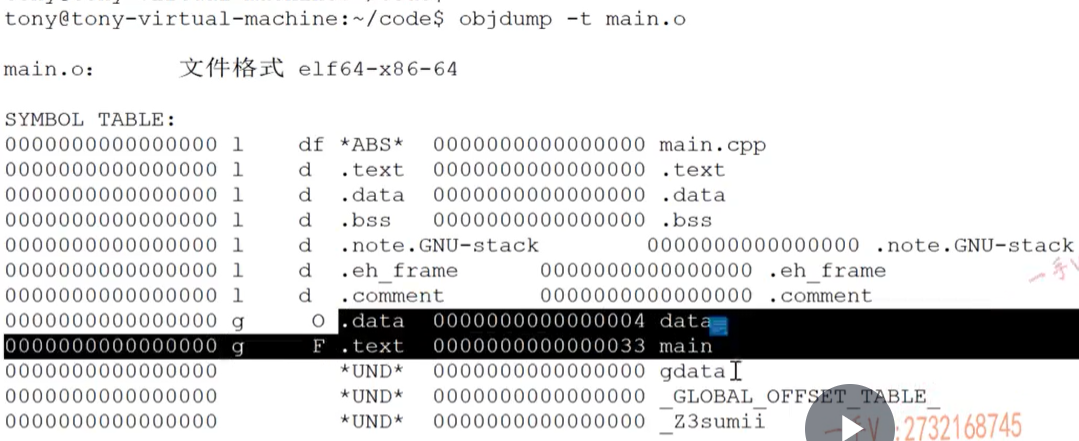
- 其中会标出 数据和指令存放的位置(.text和data),而引用的暂时标记为UND(可以出现很多UND,但是在代码中只能定义一次,要不就是重定义了)
- g:global l:local,链接的时候只能链接global的符号
- 编译过程中不分配地址,前面的地址都是0;但是指令在编译阶段就已经产生了,
链接
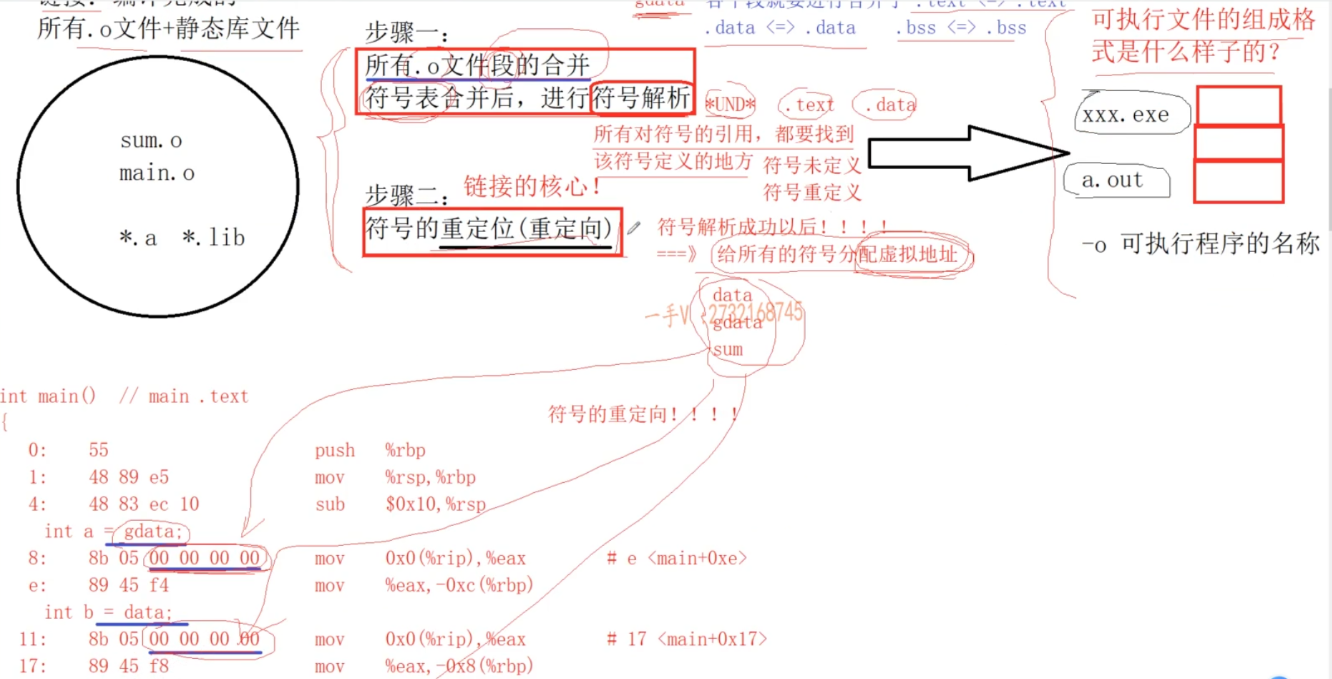
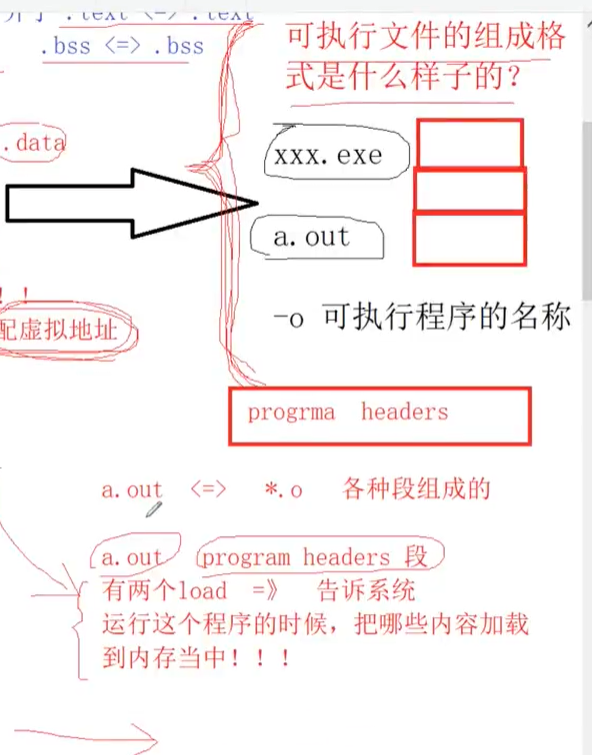
- 第一步:合并编译后的.o文件的相同段(所以可执行文件也是一段一段的),并分配虚拟地址
- 符号重定向:符号解析成功后分配虚拟地址,把虚拟地址写回指令中叫符号重定向(因为编译后不分配地址,地址都为0)
可执行文件
和.o文件一样都是由段组成的,但是多了progrma heads,用于指明把哪些内容加载到内存
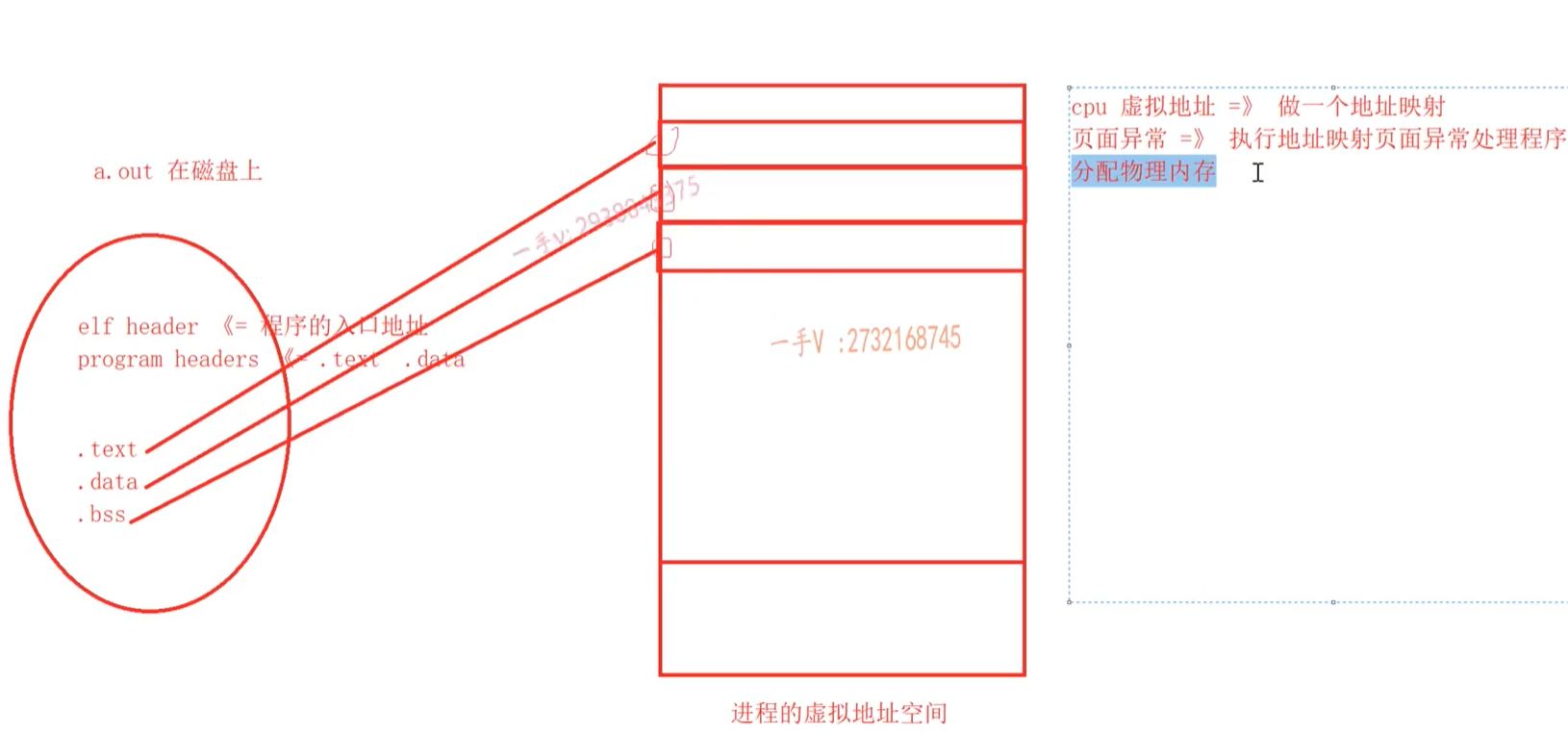
此时.o文件在磁盘上,并有了虚拟地址,之后就是操作系统虚拟地址到物理地址的转换了
C++基础知识
C++的new和delete
new和malloc的两个区别


delete和free的区别
- 无论是开辟数组还是单个元素 都是free(p)
- 而单个元素 delete p;数组 delete[] p;
new有多少种?
- 定位new 是把data赋值为50,也就是在指定的内存上填充值

C++的const、指针和引用

C++和C中的const区别
- C中的const并不是完全意义上的常量,只是在语法上规定了a不能作为左值再次赋值,实际上还是变量,因为可以用指针修改,所以也不能初始化中定义数组的长度(打印出来的值全是30)
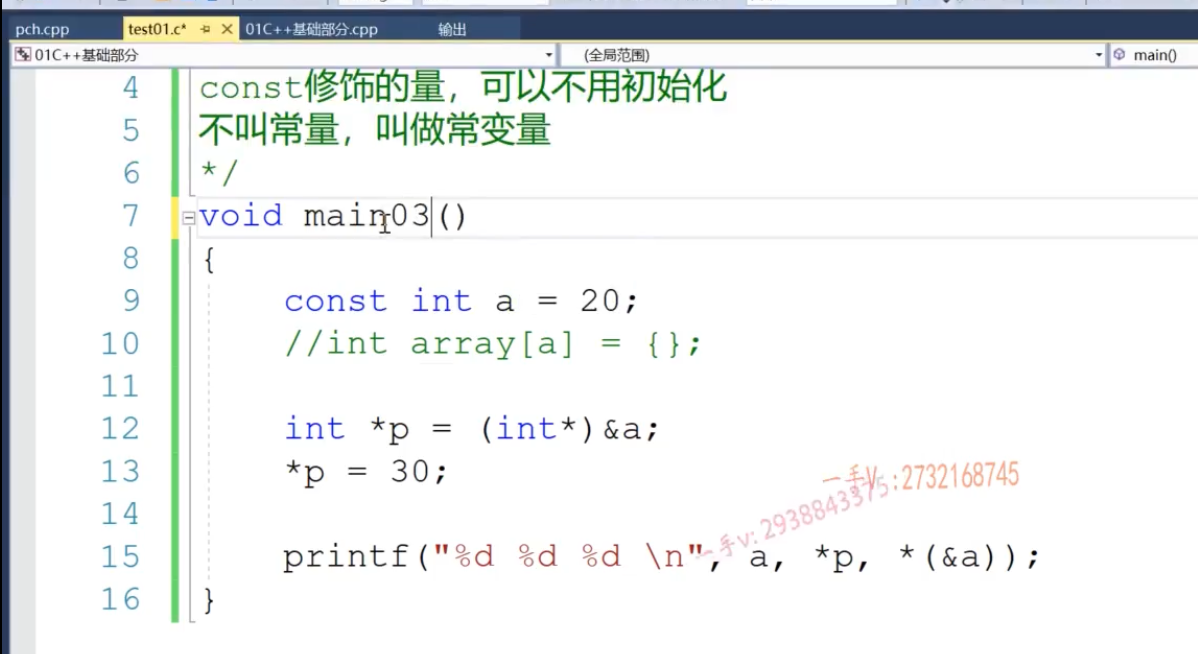
- C++中必须初始化,但是是所有出现const的地方直接用20代替。所以*p=30确实改变了a内存的值,但是*(&a)是直接变成了*(&20),所以输出还是20

- 假如用一个变量初始化(变量的值只有运行的时候才知道),可以运行,但是就退化成常变量了,和C中一模一样了
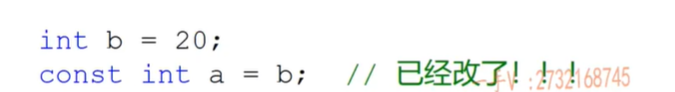
const和一二级指针的结合应用
const和一级指针的结合
const修饰的量常出现的错误是:
- 常量不能再作为左値<=这样会直接修改常量的値
- 不能把常量的地址泄露给一个普通的指针或者普通的引用变量< = 这样会间接修改常量的值,所以必须
const int *p = &a
const 和一级指针结合:
- const 修饰离它最近的类型,可以把const和离它最近的类型去掉,剩下的部分不能改变了;
- 或者可以认为const修饰最大范围内能修改的变量:
- 比如
const int*p,*p被完全包含,所以不能变;int *const p,只有p被包含,所以p不能变。
const int *p = &a:可以改变p的值,不能改变*p的值,也就是可以改变地址,不能改变地址对应的值int const* p:和上面的一样!因为*和int不一样,不能单独定义变量,所以const修饰的还是intint *const p: 修饰的是·int*,所以不可以改变p的值,可以改变*p的值,也就是不可以改变地址,可以改变地址对应的值const int *const p = &a:最严格的指针,地址和值都不能改变,第一个const修饰int不能改变*p,第二个const修饰int*不能改变p。
- 类型转换总结:


- 注意这两个输出都是
int *类型的,const后面没有指针就可以忽略
const和二级指针的结合
- q的值是一级指针的地址;*q的值等于p的值等于a的地址;**q的值等于*p的于a的值
- a的类型是int,&a的类型就是int*
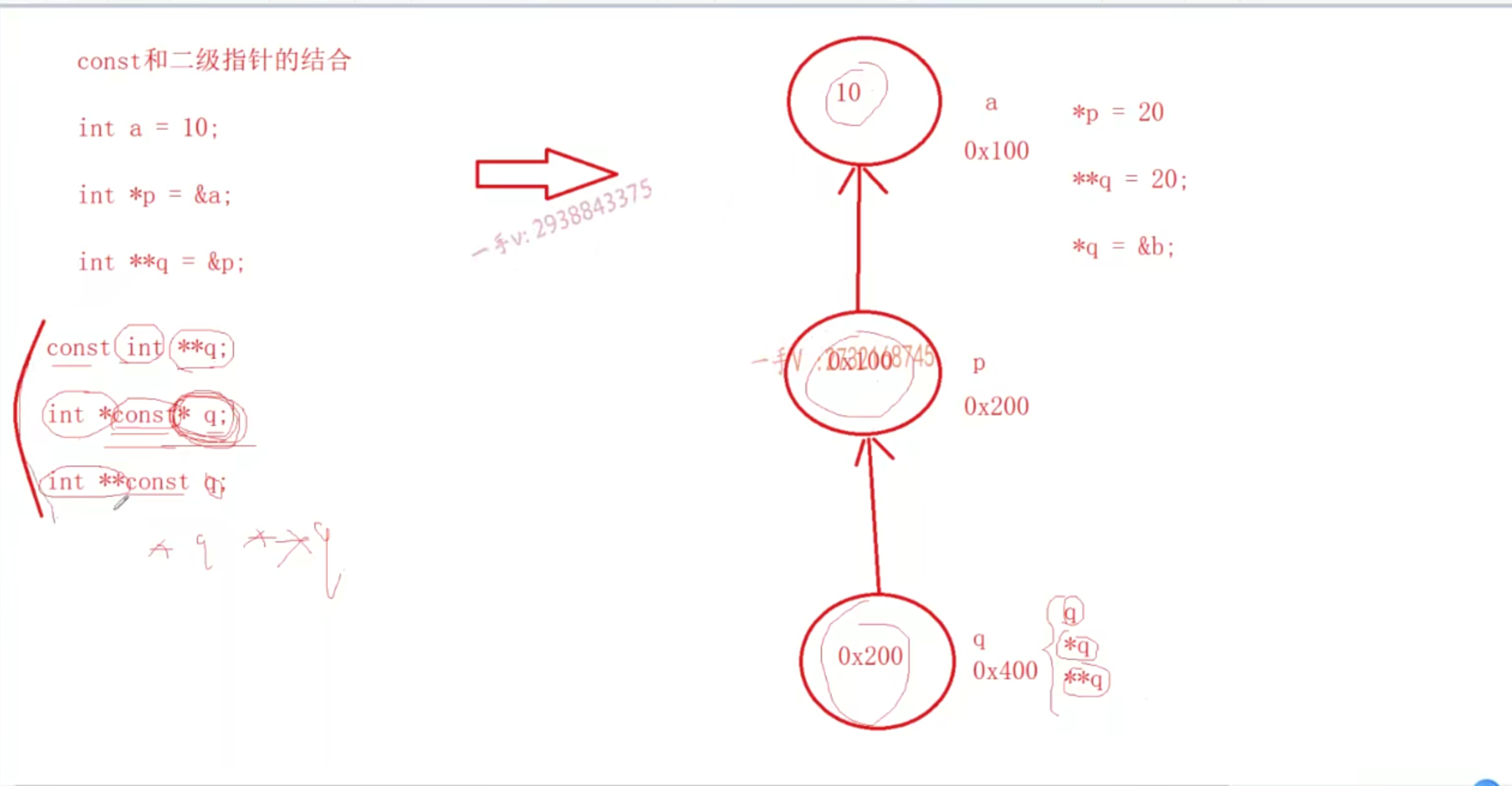
注意二级指针const无论在左面还是右面都不行

- 这个是不行的,二级指针const无论在左面还是右面都不行
- 因为
const int **q表示a是一个常量无法被修改,而右面的int *p没有const说明可以通过p来修改a,这样就冲突了(这个想法是错误的)- 正确想法:***q的类型是const int *,说明可以进行
const int b = 20 ; \*q = &b,两边都是const int *类型。**但是*q和p都等于a的地址,p不是一个const,那么这就说明把一个const类型的地址放到了一个不是const类型的地址中,错误- 也就是*q这块地址有两个名字,一个是
*q,一个是p,第一个名字是const类型,第二个不是const类型的,所以不能把const类型的地址放到这块内存,必须两个名字都为const类型才可以。- 所以没有什么多级指针,只有一级指针,
const int **q 代表 const int* *q,前面的都是类型,代表这个指针(*q)类型是个地址,而int *q,代表指针(*q)是个int的数。- 也就是二级指针的重点是有两个名字代表了同一个地址,对这块地址的操作就要小心
第三部分注意const修饰的是*,那么两面同时不看前面的int*,发现和第一部分是一样的


C++的左值引用和右值引用


指针和引用在汇编层无论是定义还是赋值都没有任何区别

所以不能int&b = 20;必须先定义a,然后int&b=a;因为20的地址是取不到的。
- 结果是20 4 20 ,可以认为引用就是别名

右值引用
- 不能int&b = 20;必须先定义a,然后int&b=a;因为20的地址是取不到的
- 但是可以int && c = 20; 汇编层面是给一个 临时地址,然后再放到c中
- int && c = 20和 const int & c = 20 在汇编层面是一模一样的

const、指针和引用的结合使用

注意要强制类型转换才能转成地址
注意const的位置,不能放在*前面;和
int *&&p是一样的
const int *&q = p可以还原成const int **q = &p就和前面的例子一样了所以有引用的时候让你判断对错,换成指针比较好看一点
inline内联函数和形参带默认值的函数
形参带默认值的函数
- 对于函数和函数的参数编译器是从上到下,从右往左执行,所以要形参的默认值要从右往左给;并且调用的时候是从左往右赋值的,那么也说明形参要从右往左给默认值(但是编译器压栈还是从右向左)
- 调用的时候直接给立即数比给变量效率高,因为编译层面上少了一次移动,直接压栈

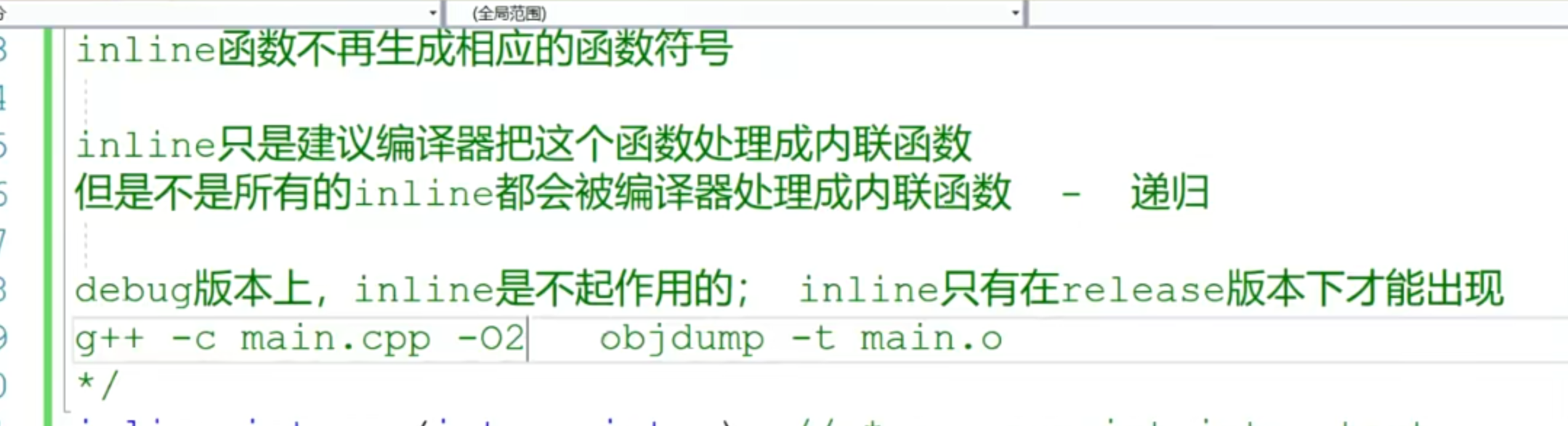
inline内联函数
- 为什么要内联函数?因为调用函数的时候有参数压栈、函数栈帧开辟的一系列开销,当函数的内容很简单比如x+y的时候,调用函数开销远大于内容计算的开销,所以就要用inline
函数重载
- C不能实现;只有C++能实现
- 因为C在编译产生符号的时候只有函数名;而C++是函数名+参数列表
- 所以问能不能重载要考虑产生符号是否相同的问题,比如只有返回值不同就不能算重载,因为产生符号是相同的
- 在同一个作用域才可以重载,比如都在全局作用域。如果定义到了局部作用域,那么会就近调用这一个函数,重载失效
- const int 和int 不能重载,编译器都看作是int
- 函数重载属于静态多态,因为函数是在编译期间就要选择指定的;动态多态指的是运行期间调用

- C和C++的互相调用
- 注意都是在C++里做的,只有C++能识别 extern

- C++调用C,同样要扩C++的函数体
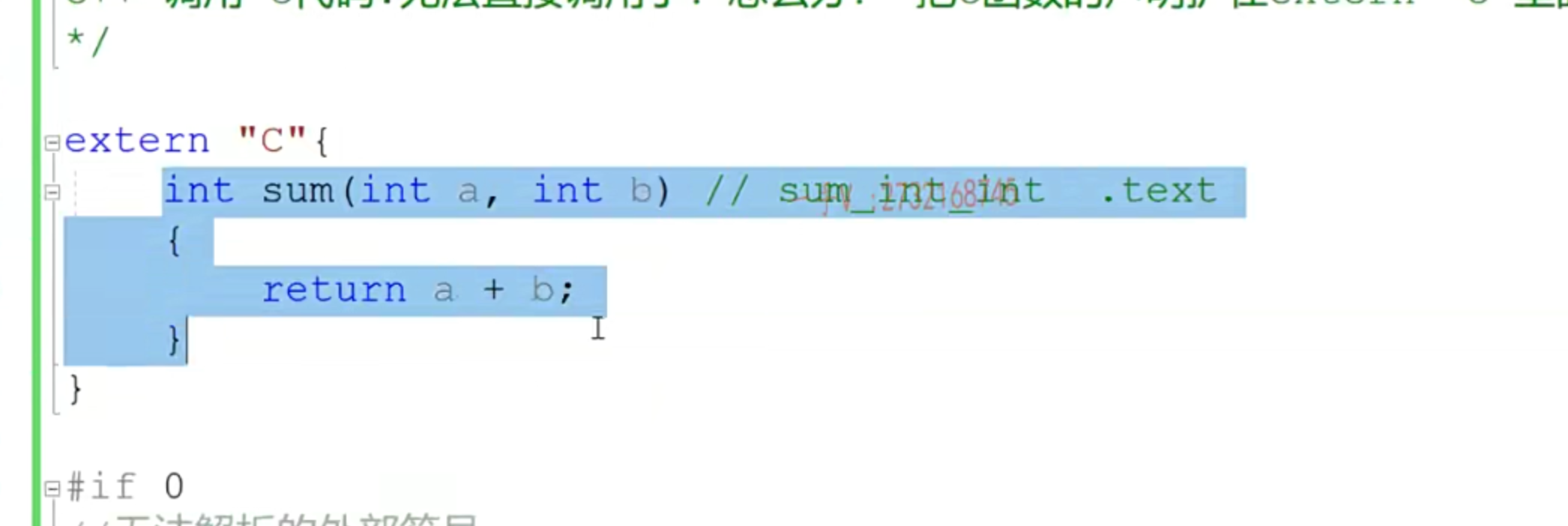
- 这样写保证无论是C还是C++编译器,最后都可以被C文件调用

类和对象、this指针
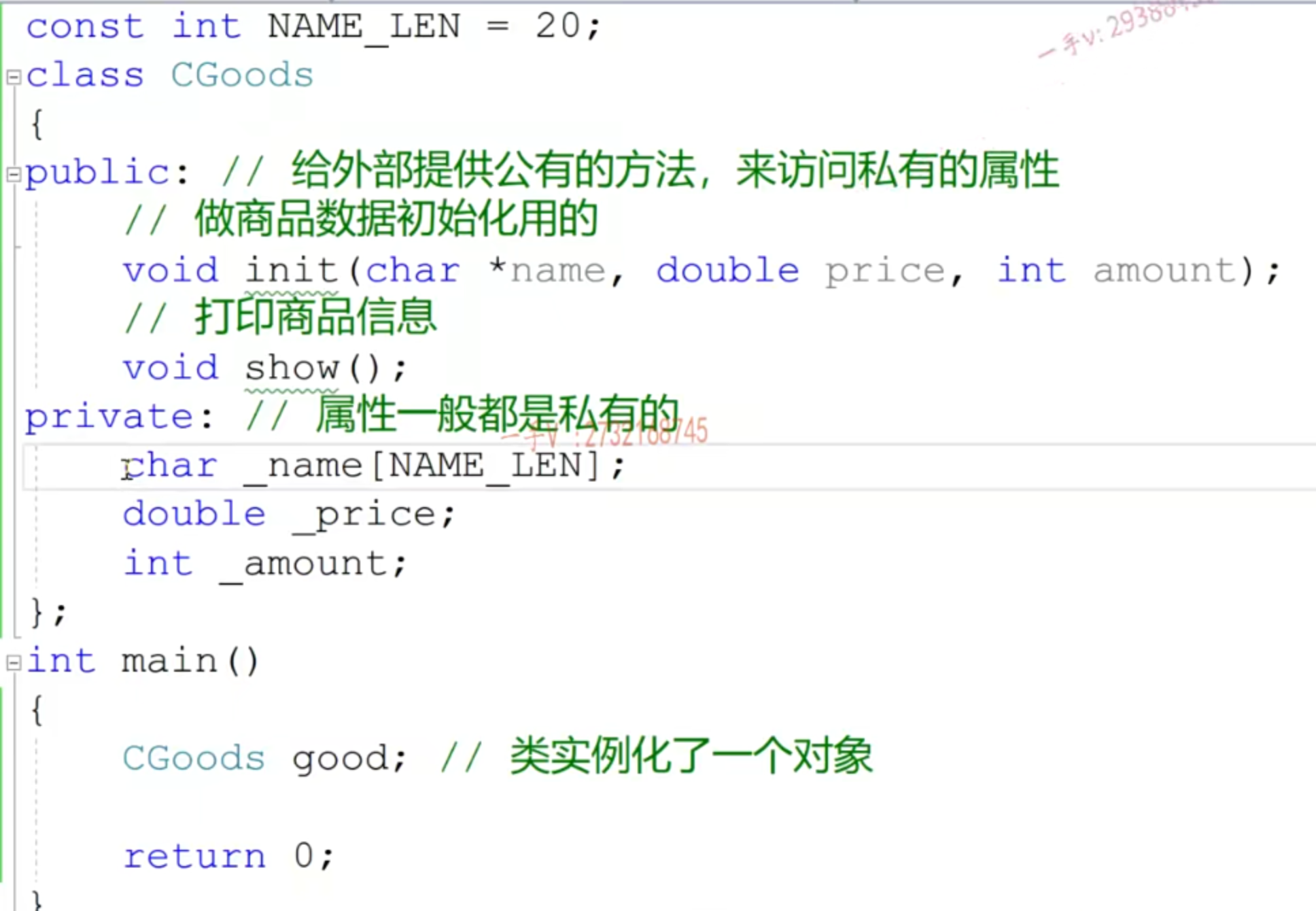
- 注意有指针要➕const,防止改变私有成员变量
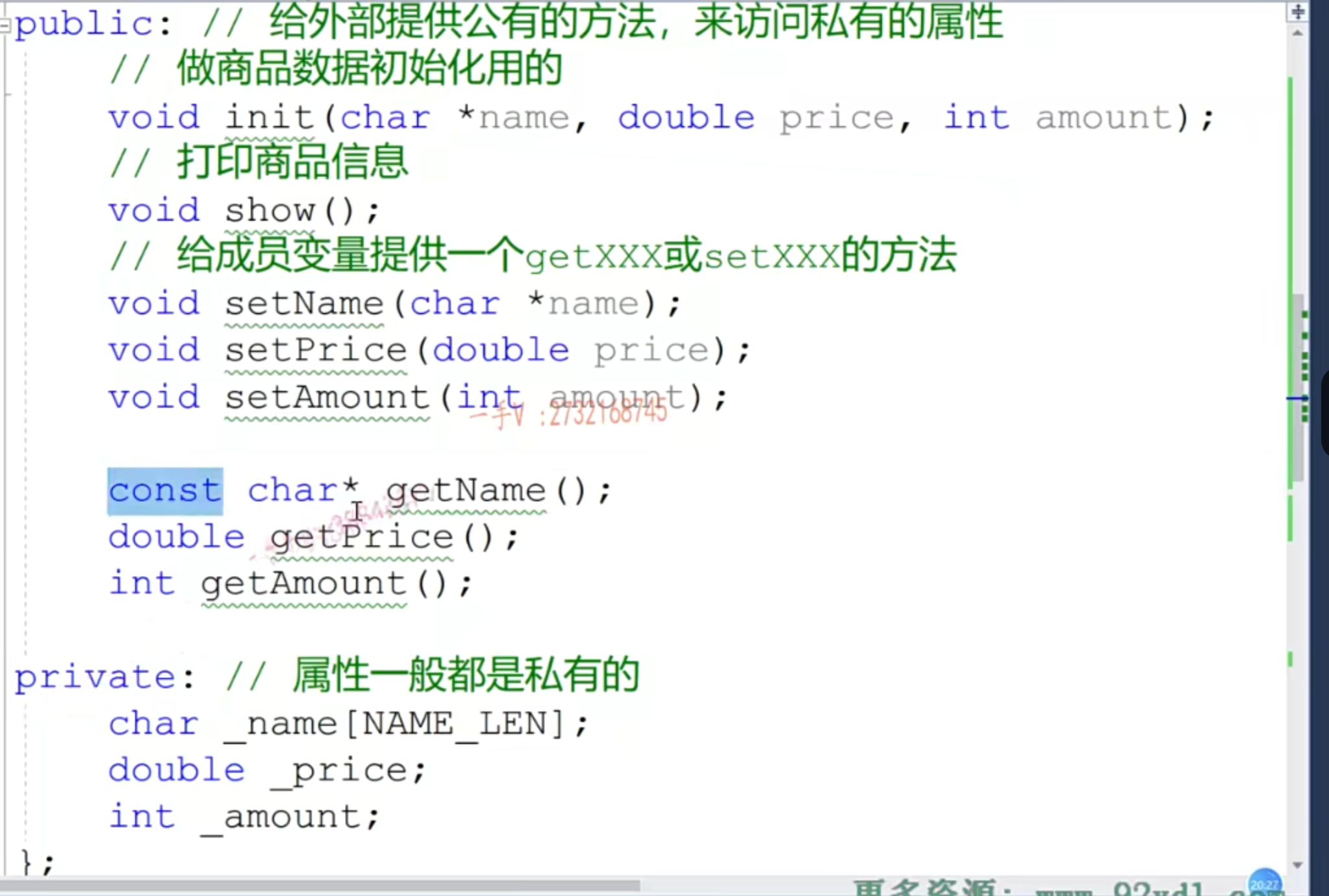
- 类中的函数会自动看成inline函数;而类外定义的函数必须手动inline,才会看成是内联函数
- 传递字符串的时候,常量指针必须定义为const,编译器防止解引用修改
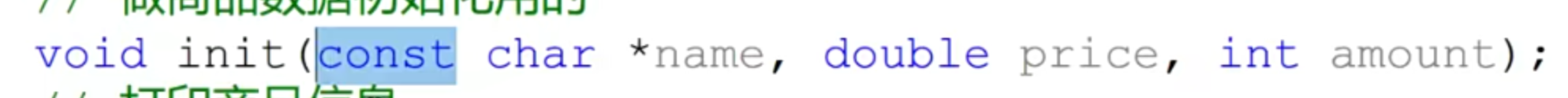
- 算类占用的空间,只看成员变量就行,和成员函数无关

- 既然成员函数只有一套,那怎么知道处理那个对象呢?


构造函数和析构函数
- 名字都和类名一样

- 构造和析构避免了自己定义init和release需要自己用对象调用的问题
- 最后在return的时候从栈中析构(也就是先构造的后析构,后构造的先析构)
- 构造函数是在堆上开辟一个内存,定义对象是在栈上开辟内存
- 所以定义对象的占用的空间:对象的大小(也就是成员变量的大小,记得字节对齐)+构造函数在堆上开辟的大小
- 构造参数可以重载,析构只能有一个

- 不要自己调用析构函数,因为会把对象的内存delete,这时候对象就没了,不能再操作了

- 内存无非有三块数据,堆和栈
- SeqStack s:是开辟在栈上,并且通过
.访问- SeqStack *ps是开辟在堆上,并且通过
->访问- 这跟leetcode链表对象的初始化是一样的!

- 注意在堆上必须要手动delete,delete包含了调用对象的析构函数和释放指针两个作用

- 数据段的对象程序启动时构造,结束时析构(全局的对象)
- 栈上的对象定义的时候自动构造,return的时候自动析构。(
SeqStack s)- 堆上的对象(
SeqStack *ps),new的时候自动调用构造函数,必须手动delete才能自动调用析构函数

对象的深拷贝和浅拷贝
- 如果自己不定义构造/析构/拷贝函数,程序会默认提供空参数的 这三种函数

- 浅拷贝(系统默认给你的拷贝构造函数):拷贝同一块内存
- 浅拷贝函数指向的是同一块内存,所以上图的代码不能正确运行,因为结束的时候要析构同一块内存两次

- 类中对数据的拷贝一般用for循环,而不能用memcpy直接复制,因为这做的也是浅拷贝,如果放的不是int而是指针,那么复制完会出现和上面一样的问题。
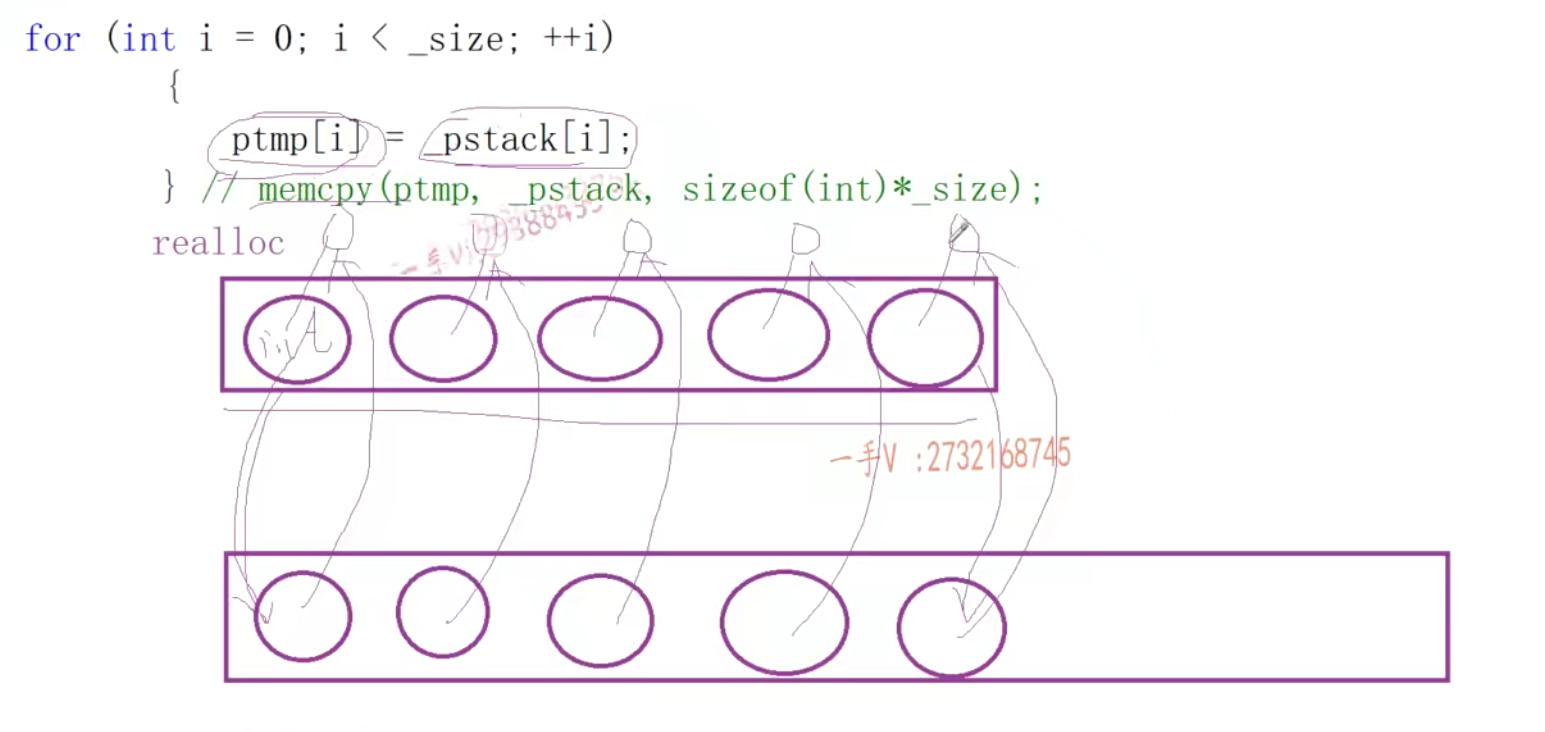
- 所以浅拷贝是否有问题主要看这个对象有没有占用(指向)外部资源,如果只是一个int,那么不会有问题,但是如果指向外部的内存,那么在析构的时候就会有多次析构同一块内存的
- 问题了
深拷贝(自定义拷贝构造函数)
其实就是要自己在new开辟一块堆内存,就不会有浅拷贝的问题了

- 自定义赋值函数
- 默认的赋值函数也是浅拷贝
- s1,s2都定义后这样复制问题更大,因为此时s2指向的内存都丢了,并且指向了s1指向的的内存


- 这里要把
=运算符重载,函数体内应该先把s2自己的内存delete,然后for循环复制数据(同时防止一下自己赋值给自己)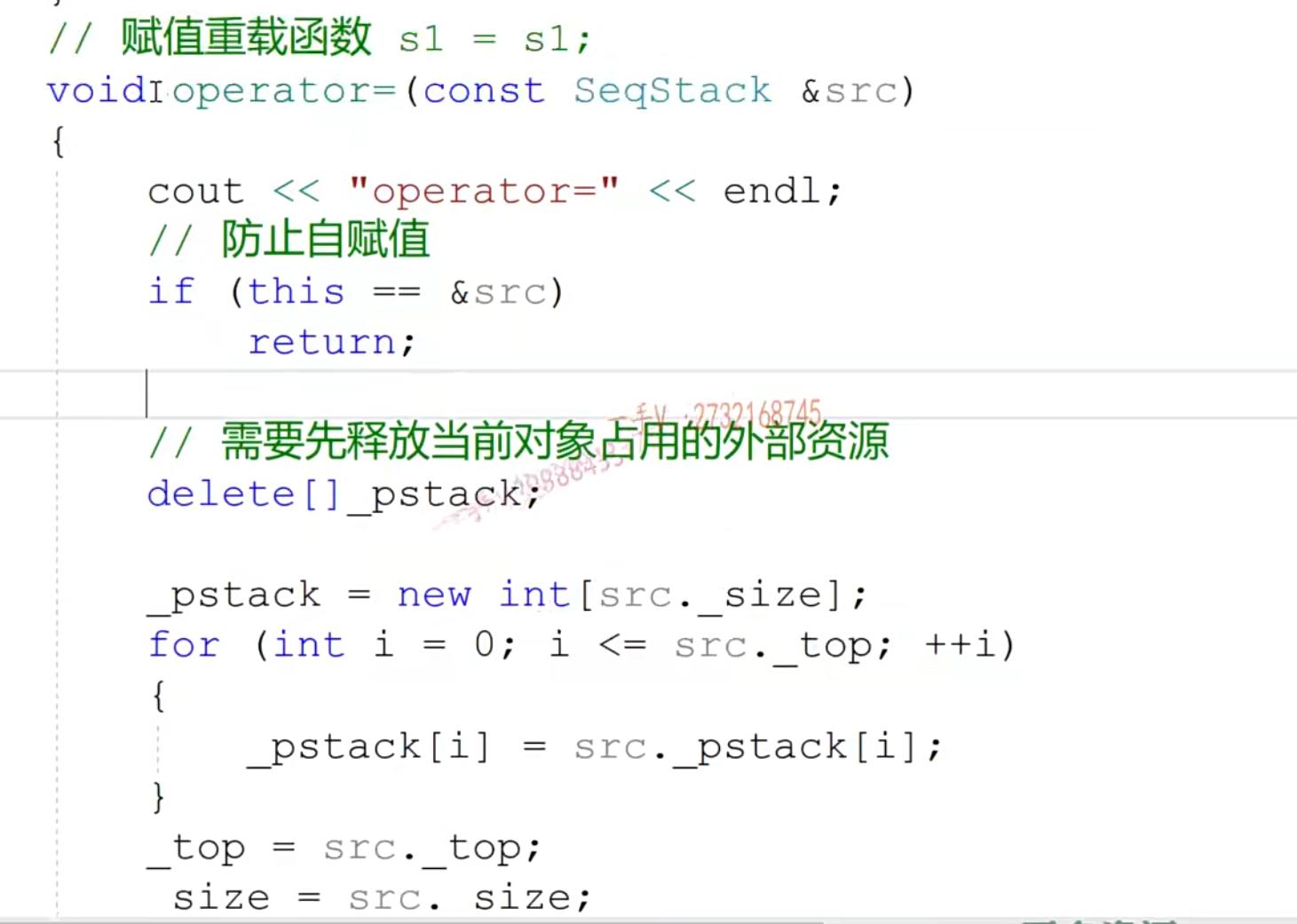
类和对象实践
- 构造函数遇见指针的时候,要考虑
- 自身成员变量要先new开辟内存
- 外部传来的指针是否为空?
- 如果为空不要设为nullptr,因为这样后面所有的成员函数都要判断是否为空,设为一个0字符,那么后面的就不需要判断自己的成员变量是否为0了。
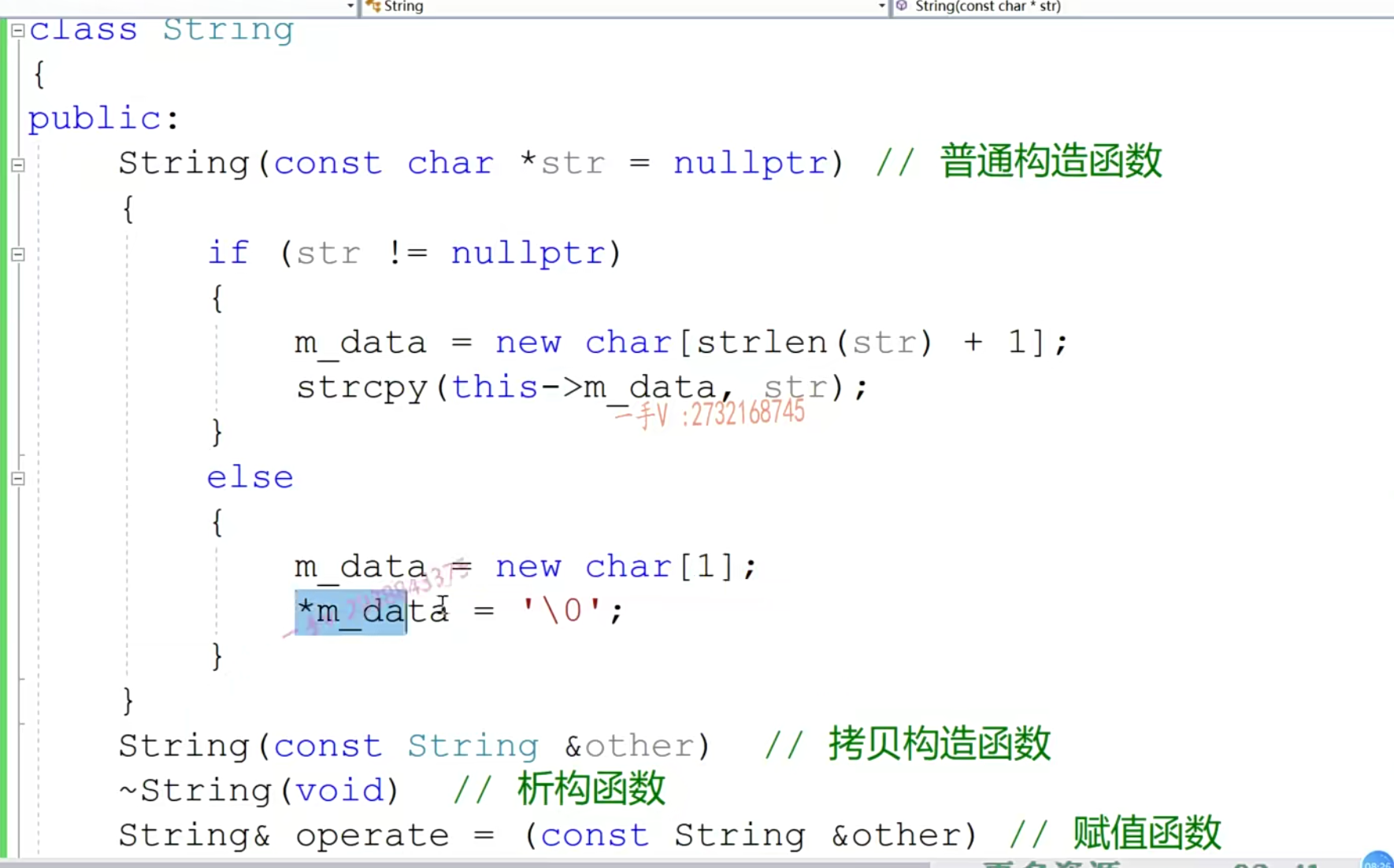
- 注意第二部分第一个不是赋值重载,因为赋值重载是对象已经被定义完成之后的操作。这个是对象在构造过程中的操作,所以是调用拷贝构造函数。
- 这三部分中的语句都是等价的

- 循环队列类的实现




- 拷贝构造和赋值构造

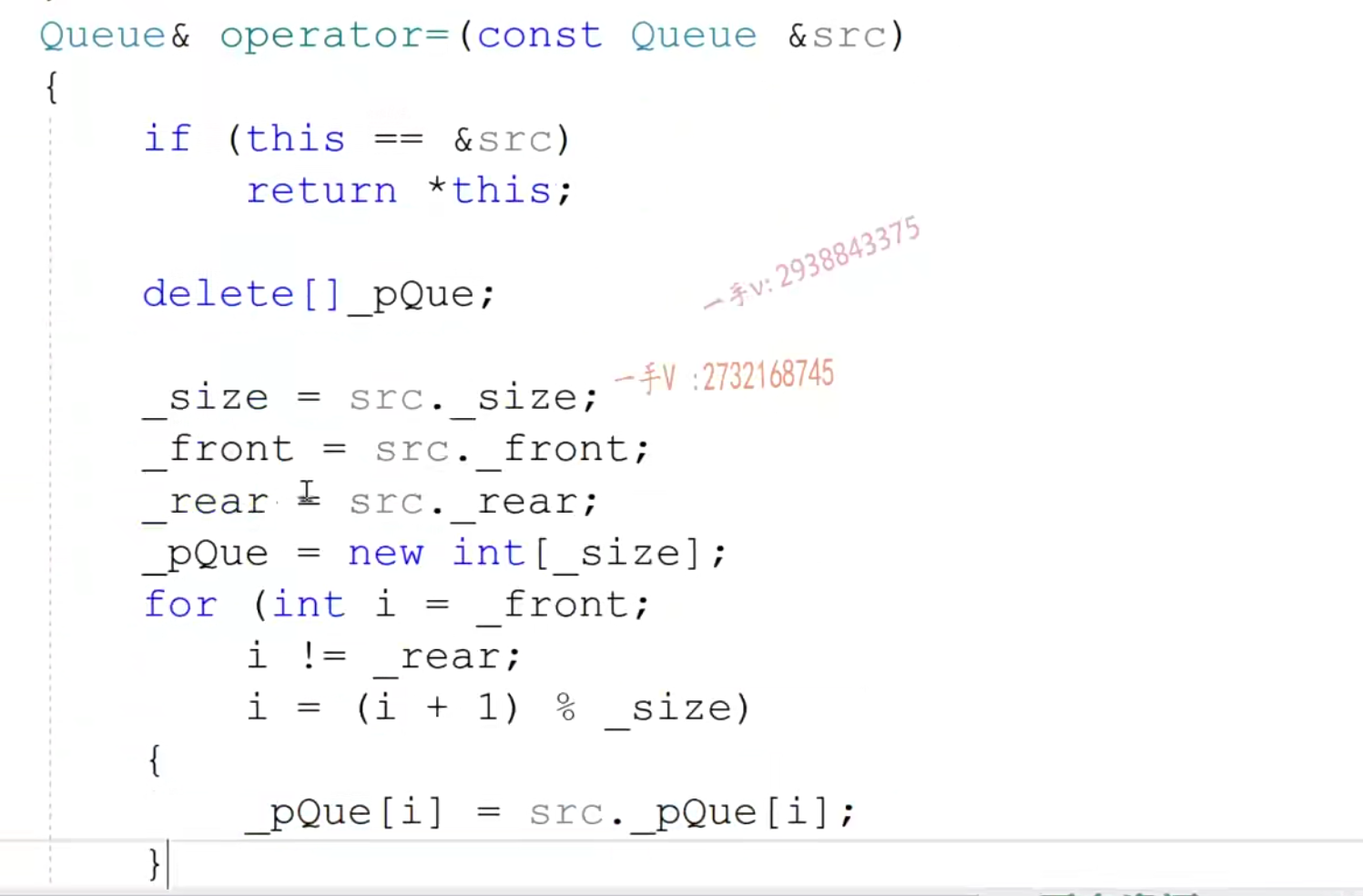

构造函数的初始化列表
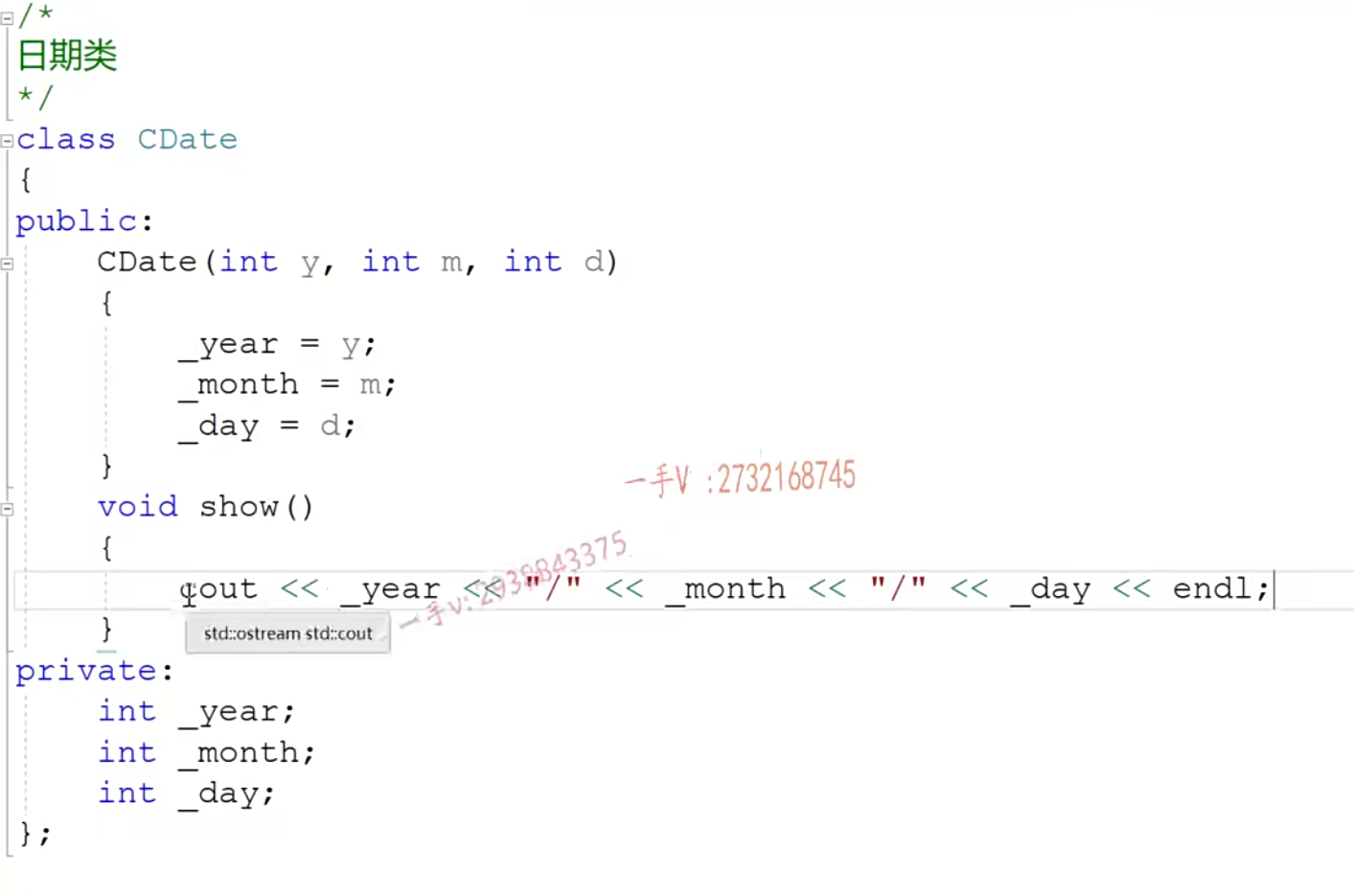
- 成员对象


- 当成员变量中有别的类的对象的时候,那么在构造函数中也要初始化构造成员对象
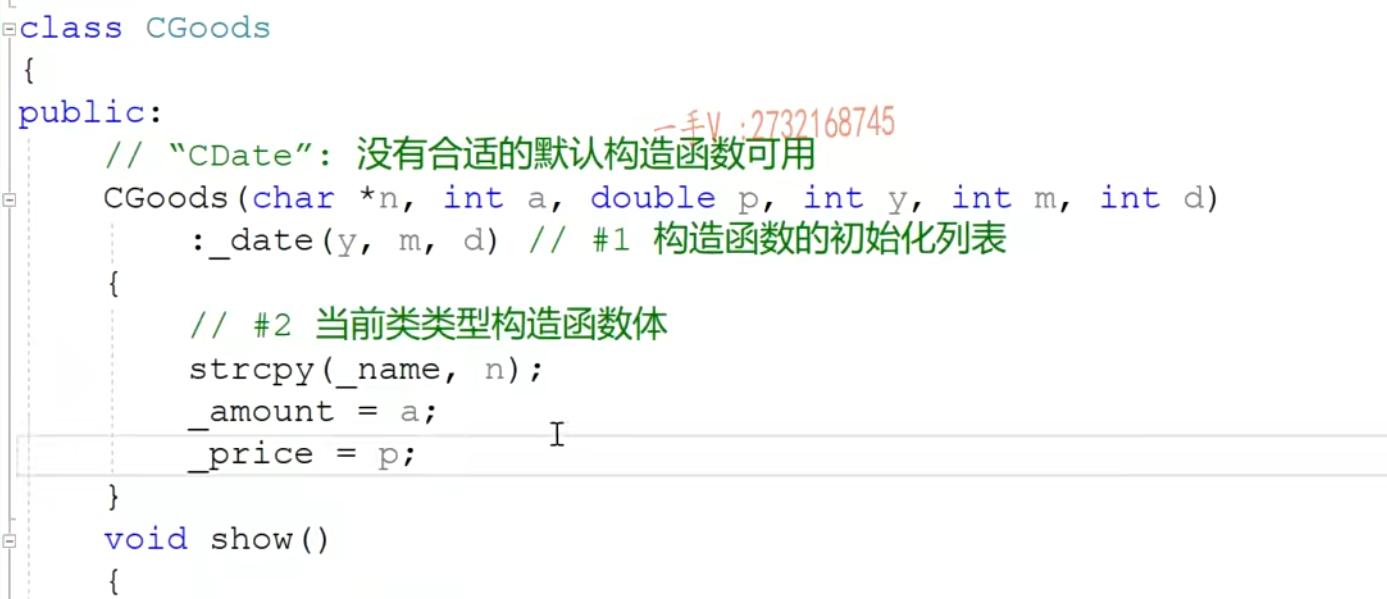
- 不要在构造函数体里这样做,因为这个时候用的是赋值构造函数,而对象_data还没构造出来呢,所以会出错

- 注意这里ma是无效值,初始化列表的顺序 和成员变量定义的顺序相同

类的各种成员方法和区别

- 比如统计类所有对象的数量,可以定义一个静态变量。也可以定义全局变量,但是就不是面向对象了
- 属于类级别,所以不占用内存

- 可以同时创建一个静态成员方法,这样就不用通过对象来调用函数,而是直接用类调用函数;访问所有对象共享的信息

- 本质区别在于普通方法产生this指针,而静态成员方法没有this指针
- 静态方法只能访问静态成员变量,不能访问普通成员变量;因为没有this指针,不知道调用哪一个对象

- 创建一个常对象,那么调用普通成员方法会有问题。因为调用函数实际上是传递一个this对象指针,但是常对象的指针是const*;不能吧一个const指针传递给普通的指针(一级指针的基础知识);不能把const *实参传递给*的形参

- 解决办法很简单,把想要调用的成员也变成const类型;注意const位置,在函数()最后
- 只读的都实现成常成员方法,这样无论传过来的实参是否是const都能用
- 常成员方法不能修改变量,因为是 const *this指针,所以*this就不能改变了(也就是this指向的值不能变);而实际上函数体里每一个变量的读写都省略了
this->price
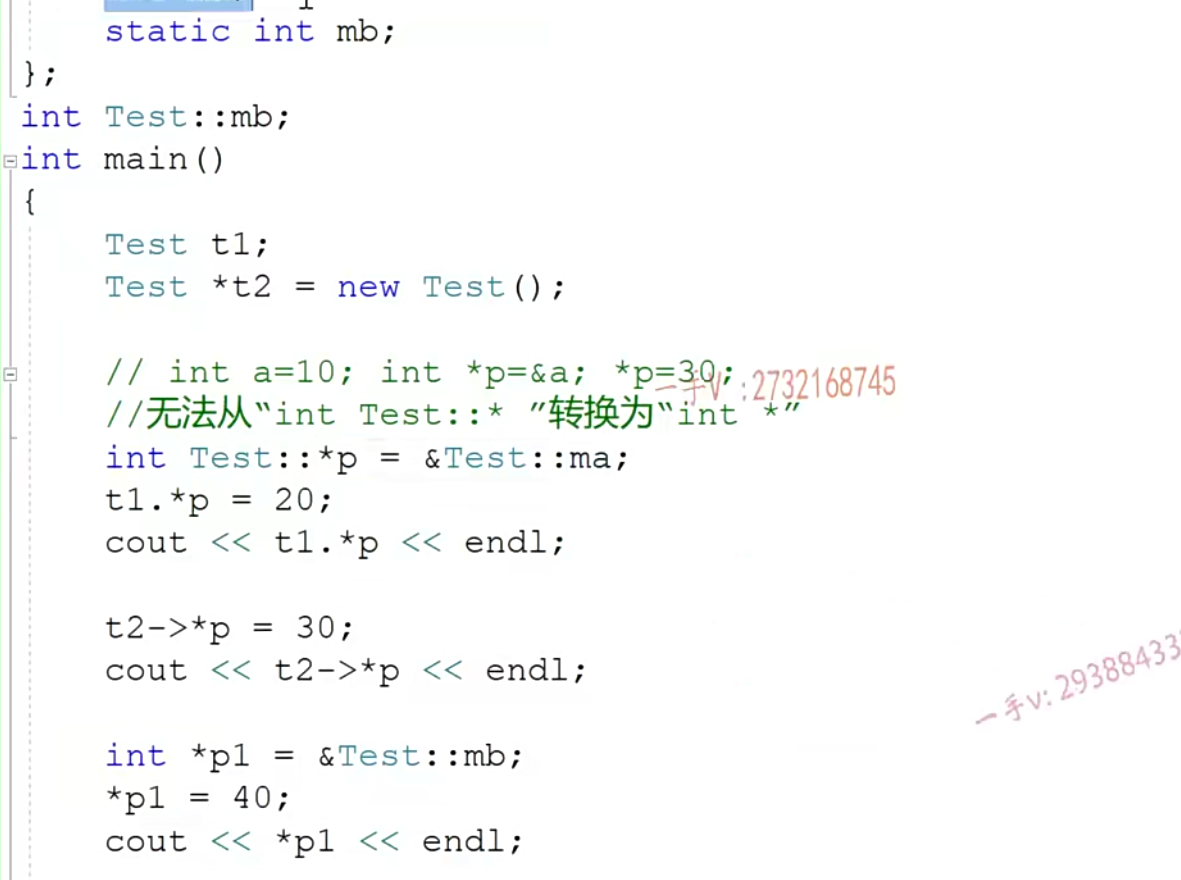
指向类成员(成员变量/方法)的指针
- 定义指针要加上类的作用域
- 调用指针,要通过具体的对象调用
- 静态成员变量/方法除外,可以看做全局变量/方法,只不过落在了类的作用域中
- 指向成员变量的指针
- 定义一个指针用于指向成员变量一定要加作用域,否则不知道是哪里的成员变量,也就是要
Test::限定- 同时调用一定要通过具体的对象来调用

- 而静态成员变量不需要类作用域限定,因为静态成员变量是不依赖类的
指向成员方法的指针
和上面一样,指向普通成员方法一定要依赖作用域
注意函数指针的定义方法
- 定义是
void (*p)() = &fun()- 调用是
(*p)()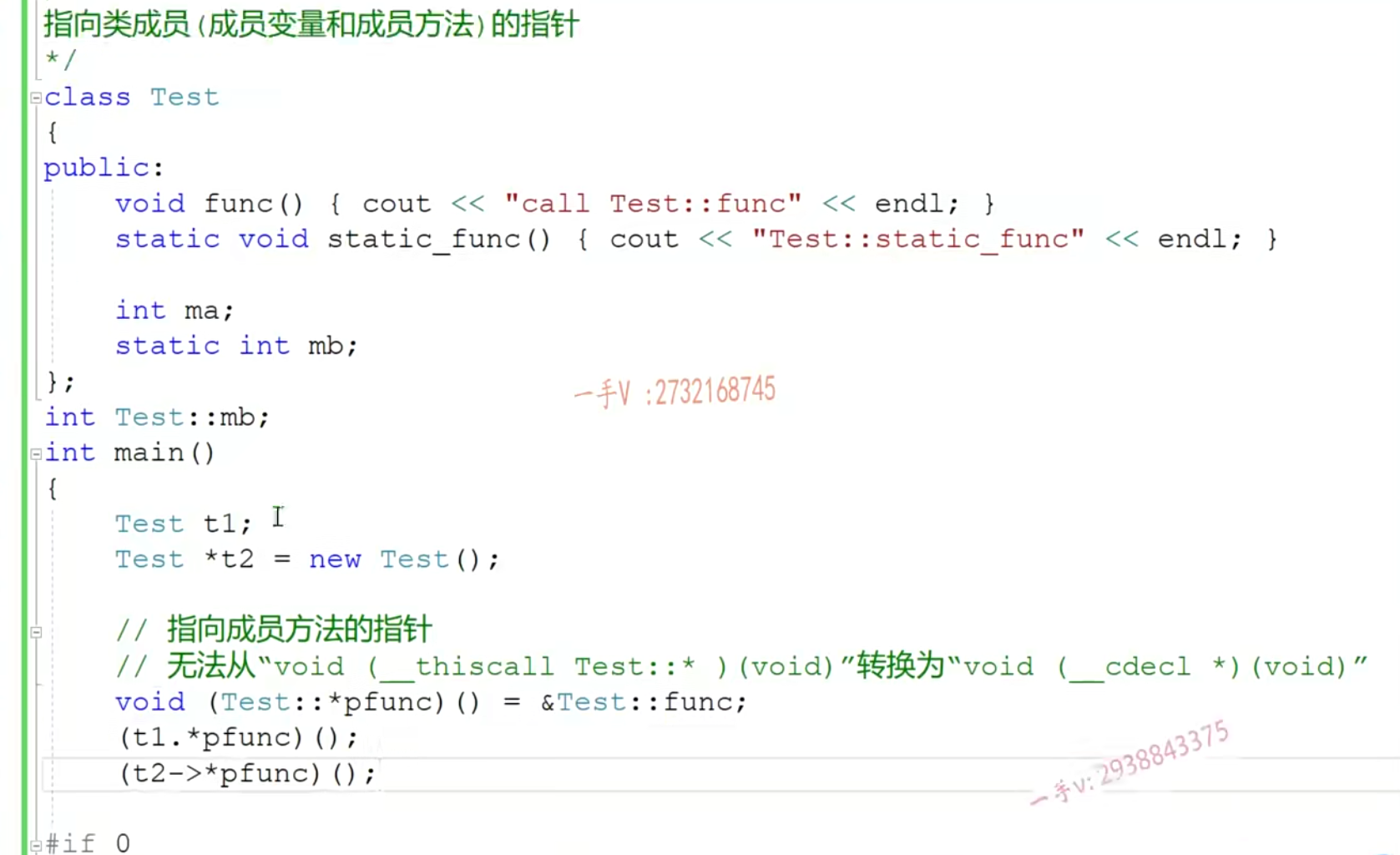
理解函数模板
- 模板目的:只关心代码的逻辑,而不关心具体的类型


- 模板函数


- 不写<>也可以通过传入参数的类型来推断出T的类型,但是参数的类型必须一致;最下面的就不行了

- 特例化模板

模板不能放到其他CPP中调用,编译的时候会出错,因为只有被调用的时候才会被编译,声明的时候是不被编译的。所以要放在.h头文件中。
- 除非在声明的时候就实例化(尽量别用,否则就失去了模板的目的了)

- 非类型参数(T叫类型参数)

